Nullmax研习社 | 从数据闭环到混合数据增强,关于自动驾驶数据的那些事
发布时间:2022-11-29
今天,小编将继续为大家带来Nullmax感知部总监兼计算机视觉首席科学家成二康博士做客汽车之心·行家说栏目的内容整理下篇,关于自动驾驶的数据闭环及混合数据增强的简要介绍。Nullmax正通过将这些技术应用到不同的量产项目中,推进自动驾驶系统的迭代升级。对于自动驾驶而言,数据具有至关重要的技术驱动作用,通过数据闭环高效收集、利用海量的真实数据,是自动驾驶研发和落地的一项核心能力。与此同时,在无法充分获得所需真实数据的情况下,大规模地生成虚拟样本也是一种可行的方式。
对于自动驾驶来说,真实世界的驾驶环境变幻莫测,驾驶场景层出不穷,训练有素的软件算法也会面临长尾效应带来的一系列问题,遇到一些很少遇到但是很难应对的极端场景。因此,针对自动驾驶的长尾问题,Nullmax打造了高效的数据闭环,支持行泊一体方案的大规模应用,并且探索了大规模地生成虚拟样本数据,运用混合数据增强方法解决少见目标检测方面的相关难题。
这样的话,可以最大程度、最高效率地在真实场景中收集和利用困难样本数据,同时在真实场景数据难以满足需求的情况,通过合成虚拟样本来解决数据难题。
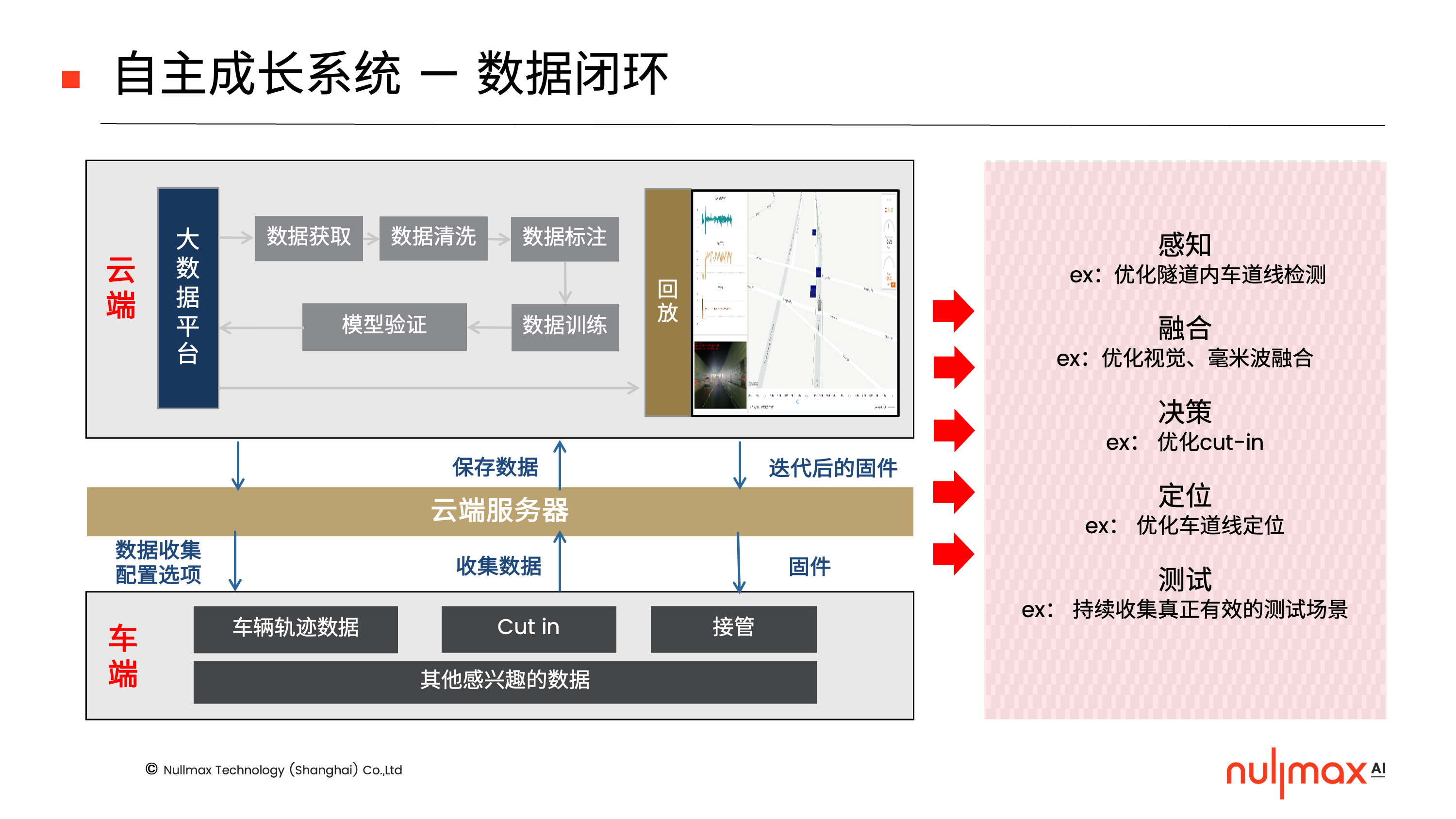
数据闭环
Nullmax的数据闭环,名为MaxFlow自主成长系统。它包含了车端、云端两大部分,车端源源不断地获取数据,云端对数据进行分析,完成获取、清洗、标注、训练以及模型验证的整个闭环。
影子模式,简单来说就是通过对比人类司机和自动驾驶系统的驾驶差异,获得一些数据,提升自动驾驶系统的驾驶能力,从而逼近甚至是超越人类驾驶水平。对于感知层面来说,也是如此,比如AEB误触发,那么就可以在误触发的时候,将视觉传感器的数据进行回收,送到云端分析处理。这是一种相对被动的学习方式,此外系统也包含一些相对主动的学习方式,比如通过不确定性等进行样本的筛选。
在线的trigger方面,包括有人机一致性、时序一致性、多传感器一致性、多算法一致性、指定特殊场景等不同类型的设置。如果遇到变道失败、传感器之间结果不一致、算法结果不一致等等情况,那么就会触发相应数据的收集。
举个例子,一个障碍物在时间维度而言,既不可能凭空消失,也不可能凭空出现,这就是时序的一致性。如果一个行人在连续轨迹上消失了,那么就是典型的漏检。
另外一个例子,就是同样的一张图片,用不同的算法进行一致性的校验。比如freespace和障碍物相互校验,可行驶区域当中不应存在障碍物,不然的话就是漏检。
此外,运用多种算法校验来筛选难样本,也是非常重要的手段。比如行驶在路面的车辆,如果只检测出车轮,但没有检测出车辆,那么极有可能这是一个比较难的样本,比如涂装车、挖掘机、平板车等等罕见的车辆。这种方法也可以用来筛选一些极近距离的大车,比如油罐车、拖车、挂车等等少见场景的数据。
同样的,
 对于行人也可以通过头部的检测和身体的检测,来校验检测结果,筛选困难案例。
对于行人也可以通过头部的检测和身体的检测,来校验检测结果,筛选困难案例。
混合数据增强
对于自动驾驶而言,除了通过数据闭环在真实场景中收集困难样本之外,另外一种获取数据样本的方式,就是大规模的自动化生成虚拟样本。比如,在CVPR 2022上提出的合成数据集SHIFT,就是通过CARLA仿真几乎零成本地生成真值数据。再比如Block-NeRF,利用3个月收集的数据重建旧金山市的场景,这是另外一种生成数据的方式,通过一些样本的视角来生成其他视角的虚拟图像。此外,通过计算机图形学和生成式模型相结合,也能够以Neural Rendering的方式生成大量的虚拟数据。
因为对自动驾驶而言,即使专门去筛一些数据,获得的数据量仍可能还是很小。收集一些少见的样本,比如锥形筒相关的场景,其实依然很难。
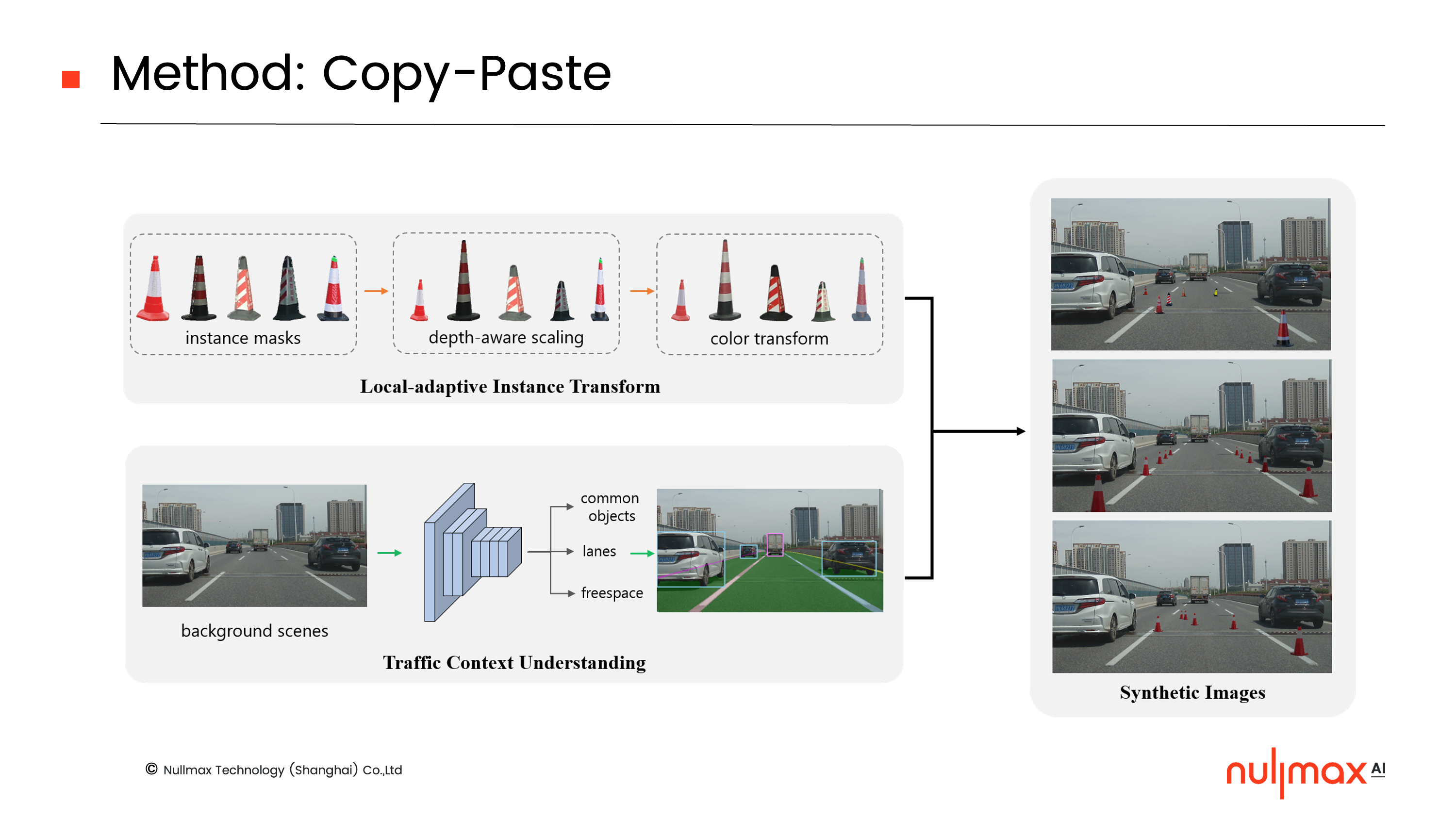
所以我们当初的想法是,既然拥有大量没有锥形筒的真实场景,那么能不能将锥形筒的mask(掩膜)贴到这些真实场景图片上面,几乎零成本地自动生成大量少见样本呢?这就是我们想要通过混合数据增强来实现的目标。
这当中有两个非常关键的问题,一个是锥形筒mask贴到什么位置,一个是怎么贴mask。因此,我们提出了一个多任务的深度学习网络,为交通场景提供相应的约束,确保mask沿着车道线贴到freespace上,而不是车上。同时,还提出了一个局部自适应的颜色变换,让mask能够自动适应每张图片本身的颜色分布。实验结果显示,对锥形筒这类少见样本来说,如果只有少量数据,检测效果其实比较一般。但是在结合我们的混合数据增强方法后,检测效果可以大幅提升。Nullmax已经开源相应的ROD(Rare Object Dataset)数据集,当中包含1万多张的数据,分布在不同的道路、天气和光照条件。如果大家感兴趣,欢迎登陆网站下载 https://nullmax-vision.github.io/。
篇后语
为了更好地实现行泊一体,Nullmax开发了能够自动化支持行车和泊车两类任务的感知基础架构,从而最大程度地复用软件算法。这其中,就包括了数据、训练和部署。
基于这套架构,Nullmax能够通过数据闭环收集的海量真实数据,以及大规模生成的虚拟样本,以非常高效、经济的方式提供提供丰富、充足的训练样本,对算法进行真实和混合数据的混合训练,打造出一个满足全场景自动驾驶需求的「超级大脑」。
后续,我们将介绍这套强大的感知基础架构,敬请关注!